- 公開日: 最終更新日:
robots.txtとは?書き方、置き場所、確認方法を解説
ホームページ制作において、検索エンジンのクローラーがどのページをクロールすべきか、または避けるべきかを指定するrobots.txtの設定は、SEOにも直結する重要なポイントです。しかし、「robots.txtって何?」「どのように書けばよいのか?」と迷う方も少なくありません。
このページでは、robots.txtの基本的な役割や書き方、置き場所、確認方法、設定時の注意点までを解説します。正しい設定を行うことで、検索エンジンのクロール効率を最適化し、ホームページ制作や運用をより効果的に進めることができます。
目次
robots.txtとは
robots.txtは、ウェブサイト管理者が検索エンジンのクローラーに対して、特定のページやディレクトリへのアクセスを制御するために使用されるファイルです。
ファイル名はrobots.txtとし、正確な形式で記述する必要があります。
robots.txtは、ホームページのデータを設置しているサーバーのルートディレクトリに配置され、クローラーがアクセス時に最初に確認するルールブックの役割を果たします。
たとえば、クローラーに特定のページをクロールしないよう指示する場合や、不要なリソースへのアクセスを防ぎたい場合に利用されます。この仕組みを活用することで、クローラーの効率的な動きを促し、ホームページのSEO対策を最適化することが可能です。
また、似たような仕様に、noindexと呼ばれるものがあり、以下でその違いや使い分けについて解説します。
robots.txtとnoindexの違い
robots.txtとnoindexは、どちらも検索エンジンの動きをコントロールする手段ですが役割や用途が異なります。
robots.txtは、クローラーがアクセスする前にクロールを制御する一方で、noindexはクロールは許可しますがインデックスを拒否します。それぞれを正しく理解し、ホームページ制作で最適に活用することが重要です。
noindexについて詳しくはnoindexとは?のページをご確認ください。
robots.txtとnoindexを使い分けるタイミング
robots.txtとnoindexは、それぞれに適した場面で使い分けることで、検索エンジンによるクロールやインデックスの管理を効率化できます。
robots.txtは、検索エンジンがクロールを行わないため、クロールバジェットを消費しません。そのため、開発中のテストページや管理画面など、一般のユーザーに公開する必要がないページをrobots.txtで拒否すれば、他の重要なページへのクロールを促すことが可能です。
一方で、noindexは、ページそのものはクロールしてもらいつつ、検索結果には表示させたくない場合に適しています。たとえば、古いキャンペーンや運営上必要だが検索結果には不要なページに対して使用されます。
これらの違いを理解し、ホームページ制作時に適切に使い分けることで、ウェブサイトの運営や検索エンジン最適化がさらに効果的なものになります。
robots.txtのSEO効果
robots.txtは、ウェブサイトのSEOを最適化するために重要な役割を果たします。
robots.txtを正しく設定することで、検索エンジンのクローラーが効率的にサイトをクロールし、重要なページを確実にインデックスできる環境を整えることが可能です。
特に、ページ数が1,000を超えるような大規模サイトでは、robots.txtの効果が顕著に現れます。たとえば、公開する必要のないページをクロール対象から外すことで、クローラーが本来インデックスしてほしいページに集中できるようになります。
これにより、クロールバジェットを最適化し、検索順位の向上が期待できます。
一方で、小規模なサイトの場合は、robots.txtの影響は限定的であることが多いです。ページ数が少ない場合、クローラーがすべてのページを問題なくクロールできるため、robots.txtの必要性は必ずしも高くありません。それでも、不要なページをクローラーに見せたくない場合には、基本的な設定を行う価値はあります。
robots.txtは、特に大規模サイトにおいてSEO効果を最大限に引き出す重要なツールです。適切に設定することで、SEO効果をさらに引き出すことが可能です。
robots.txtの書き方
robots.txtは、検索エンジンのクローラーに対して特定の指示を出すための非常にシンプルなテキストファイルです。このファイルを正しく記述することで、不要なページのクロールを防ぎ、重要なページを優先的にインデックスさせる環境を整えることができます。
以下は、WordPressを利用したホームページで一般的に使用されるrobots.txtの例です。
User-agent: *
Disallow: /wp/wp-admin/
Allow: /wp/wp-admin/admin-ajax.php
Sitemap: https://sample.jp/sitemap.xml
Sitemap: https://sample.jp/sitemap.rss
このように、robots.txtは特定のクローラーやディレクトリに指示を与える構文で構成されています。これを理解すると、次に解説する各要素の役割がより明確になるでしょう。
User-Agent
User-Agentは、検索エンジンのクローラーを指定するためのコマンドです。この指定を行うことで、特定のク検索エンジンにのみ指示を与えることができます。
たとえば、以下のようなクローラーが一般的に指定されます。
- すべてのクローラー:*
- Google:Googlebot
- AdSense用クローラー:Mediapartners-Google
- 画像用Googlebot:Googlebot-Image
- Bingのクローラー:Bingbot
- Yahoo!(日本以外):Yahoo
- Slurp 百度:Baiduspider
- Naver: Yetibot
- Apple: AppleBot
記述例
- User-agent: Googlebot
この例では、Googlebotに対してのみ後続の指示(DisallowやAllow)が適用されます。
もしすべてのクローラーに同じ指示を与えたい場合は、以下のように記述します。
- User-agent: *
アスタリスク(*)は、すべてのクローラーを対象とする指定です。
Disallow
Disallowは、特定のページやディレクトリへのクロールを禁止するためのコマンドです。この設定を行うことで、検索エンジンのクローラーが指定されたページやディレクトリにアクセスしなくなります。
Disallowを適切に設定することで、不要なページのクロールを防ぎ、クローラーが重要なページを優先的にインデックスできる環境を整えることが可能です。
以下は、サイト全体、ディレクトリ、特定のページを拒否する場合の記述例です。
サイト全体を拒否する場合
- Disallow: /
この例では、すべてのページがクロール対象外になります。
ディレクトリを拒否する場合
- Disallow: /directory/
この記述により、/directory/以下のすべてのページがクロール対象外となります。
特定のページを拒否する場合
- Disallow: /private/sample.html
この場合、/private/sample.htmlという特定のページのみがクロール禁止となります。
Allow
Allowは、Disallowで制限をかけたディレクトリ内でも、特定のページやサブディレクトリのクロールを許可するためのコマンドです。この設定を活用することで、柔軟にクロール制御を行うことができます。
以下は、記述例と注意点です。
- Disallow: /wp/wp-admin/
- Allow: /wp/wp-admin/admin-ajax.php
この例では、/wp/wp-admin/以下のディレクトリ全体をクロール禁止とする一方で、admin-ajax.phpのみはクロールを許可しています。
Allowを記述する際にはいくつかの注意点があります。
まず、AllowはDisallowで制限をかけた範囲内でのみ使用するべきです。Disallowで指定していないディレクトリにAllowを記述してしまうと、クローラーが混乱し、結果としてSEOに悪影響を及ぼす可能性があります。
また、Allowを使用する場合には、Disallowで指定したディレクトリを含めて記述する必要があります。
たとえば、Disallowで「/wp/wp-admin/」を設定している場合、Allowを使用して「/wp/wp-admin/admin-ajax.php」をクロール可能にする際には、ディレクトリ全体を明示的に含める形で記述しなければなりません。
これらの注意点を守ることで、Allowを効果的に利用し、クロールの制御を細かく調整できます。
Sitemap
Sitemapは、robots.txtでXMLサイトマップやRSS/ATOMフィードの場所を指定するために使用されます。この記述で、クローラーがサイト全体のページを効率よく巡回し、インデックスを作成する可能性が高まります。
記述例として、以下のように複数のSitemapを指定することも可能です。
- Sitemap: https://sample.jp/sitemap.xml
- Sitemap: https://sample.jp/sitemap.rss
このように、Sitemapを記載することで、クローラーにサイト全体の構造を伝える手助けとなります。
ただし、Google検索セントラルにはSitemapは省略しても問題ないとの記載があるため、Googleがrobots.txt内のSitemap記述を参照していない可能性も指摘されています。そのため、Googleサーチコンソールを使用して直接Sitemapを送信するのが一般的な方法です。
Sitemapを適切に設定することで、特にページ数の多い大規模サイトにおいて、クローラーの巡回効率を向上させることが期待できます。
robots.txtの置き場所
robots.txtは、検索エンジンのクローラーが最初にアクセスするファイルとして、ウェブサイトの適切な位置に配置する必要があります。
具体的には、サーバーのルートディレクトリに設置することが求められます。たとえば、ホームページのURLがhttps://example.com/の場合、robots.txtはhttps://example.com/robots.txtでアクセス可能な状態にする必要があります。
正しい場所に配置されていない場合、クローラーがファイルを認識できず、指示が反映されません。特に、サブディレクトリや別のフォルダに設置してしまうと無効になるため注意が必要です。
また、複数のサブドメインを運用している場合、それぞれのサブドメインに対して個別にrobots.txtを設置する必要があります。たとえば、https://blog.example.com/やhttps://shop.example.com/のように異なるサブドメインごとに適切な設定を行いましょう。
robots.txtの正しい配置は、ホームページ制作の初期段階で見落とされがちなポイントですが、SEOに直結する重要な部分です。適切な場所に設置することで、検索エンジンのクローラーが効率よくサイトを巡回し、不要なページへのクロールを防ぐことが可能になります。
robots.txtの確認方法
robots.txtのアップロードが完了したら、記述内容が正しく反映されているか確認する必要があります。
この確認は、Googleサーチコンソールを利用するのが最も簡単で正確です。 Googleサーチコンソールにログインし、設定→robots.txt レポートを開くと、アップロードされたファイルが正しく読み取られているかどうかを確認できます。
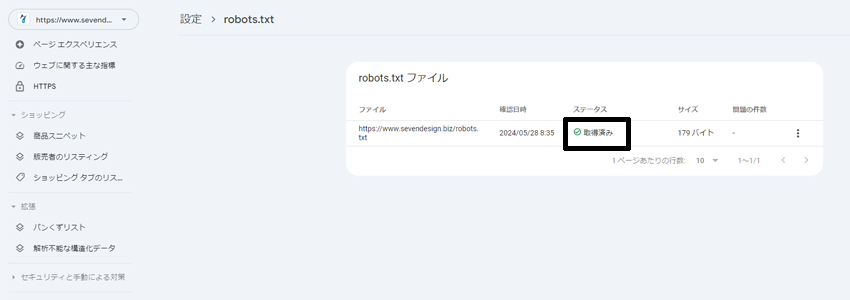
現在、robots.txt レポートでは主にステータス情報を確認する形式となっており、取得済みと表示されていれば問題なくファイルが認識されています。
ステータスには、以下のような状況が表示されることがあります。
- 取得済み:ファイルが正常に読み取られている状態
- 未取得 - 見つかりませんでした(404):ファイルが存在しない場合
- 未取得 - その他の理由:クローラーがファイルを読み取れなかった場合
取得済み以外のステータスが表示されることは稀ですが、もし問題が発生した場合は、Googleサーチコンソールのヘルプページrobots.txt レポートを参考に、原因を特定して修正することが推奨されます。
正しい確認を行うことで、クローラーが意図通りに動作し、SEOに悪影響を与えないようにすることが可能です。ホームページ制作において、robots.txtの設定後の確認作業は欠かせない工程です。
robots.txtの設定で注意すべき点
robots.txtは、検索エンジンのクローラーに対して特定の指示を与える重要なファイルですが、その設定を誤ると悪影響を及ぼす可能性があります。
ここでは、robots.txtを設定する際に注意すべき主なポイントについて解説します。
間違えて設定するとSEOに悪影響がある
robots.txtの設定を誤ると、クローラーにとって必要なページがクロールされなくなり、SEOに大きなダメージを与える可能性があります。
たとえば、重要なページやディレクトリを意図せずDisallowで制限してしまうと、それらが検索エンジンにインデックスされず、検索結果に表示されなくなることがあります。
設定後は必ず確認作業を行い、意図したとおりに設定しているかをチェックしましょう。
robots.txtを指定してもユーザーは閲覧可能
robots.txtは、検索エンジンのクローラーに対する指示を行うもので、クローラーが指定したページやファイルをクロールしなくなり、検索結果に表示されなくなります。
しかし、robots.txtはあくまでクローラーを制御するものであり、ユーザーのアクセスを制限する機能はありません。たとえば、検索結果に表示されないページであっても、そのページが内部リンクや外部リンクでつながっていれば、ユーザーはそのリンクを通じてアクセスすることが可能です。
こうした点を理解せずに機密情報や重要なファイルの保護をrobots.txtに任せてしまうと、不適切な設定が原因で思わぬリスクを招く場合があります。機密性を確保したい場合は、サーバーのアクセス制限やパスワード保護など、別の方法を利用することが重要です。
robots.txtを無視する検索エンジンも存在する
GoogleやBingなど主要な検索エンジンはrobots.txtを遵守しますが、一部のクローラーはこれを無視することがあります。
たとえば、不正アクセスを目的としたボットや、一部の小規模な検索エンジンはrobots.txtの指示を無視してサイトをクロールすることがあります。
効果が出るまでに1~2週間かかる
robots.txtの設定変更が検索エンジンに反映されるまでには、通常1~2週間程度かかります。これは、クローラーがrobots.txtを再訪問するタイミングや、変更内容が反映されるプロセスに時間を要するためです。
そのため、緊急の変更が必要な場合は、Googleサーチコンソールを活用してインデックスの削除リクエストを送信するなど、別の方法を併用するのが効果的です。
robots.txtのまとめ
robots.txtは、検索エンジンのクローラーに対する指示を行うもので、クローラーが指定したページやファイルをクロールしなくなり、検索結果にも表示されなくなります。
しかし、robots.txtはあくまでクローラーを制御するものであり、ユーザーのアクセスを制限する機能はありません。たとえば、検索結果に表示されないページであっても、そのページが内部リンクや外部リンクでつながっていれば、ユーザーはそのリンクを通じて直接アクセスすることが可能です。
こうした点を理解せずに機密情報や重要なファイルの保護をrobots.txtに任せてしまうと、不適切な設定が原因で思わぬリスクを招く場合があります。機密性を確保したい場合は、サーバーのアクセス制限やパスワード保護など、別の方法を併用することが重要です。
